Capítulo 15 Importar/exportar datos
Hemos aprendido a crear nuestros propios datos pero muchas veces los cargaremos de distintos paquetes, archivos y fuentes, y necesitaremos expotarlo. En este manual introductorio simplemente vamos a ver cómo cargar datos desde paquetes o formatos nativos de R, así como su exportación (pero las fuentes de exportación son más de las que imaginas, desde Spotify hasta el AEMET, pero lo dejaremos para un futuro manual algo más avanzado.)
Es recomendable tener los datos en la misma carpeta del proyecto pero una carpeta separada, ya que podemos tener muchos archivos y así no mezclamos dichos ficheros con los códigos que escirbamos.
15.1 Archivo .RData: pasajeros del RMS Titanic
Fuente original de los datos: https://www.kaggle.com/c/titanic/overview
El 15 de abril de 1912 se producía el hundimiento naval más famoso de la historia: el hundimiento del barco RMS Titanic. Tras chocar con un iceberg, y con un déficit de botes salvavidas a bordo, murieron 1502 de los 2224 pasajeros (tripulación incluida) que iban a bordo del navío.
¿Qué edad, sexo o cabina ocupabana los pasajeros que sobrevivieron y los que no sobrevivieron? Dicho conjunto de datos nos va a servir para ilustrar la forma más sencilla de guardar datos y variables en R, y que además ocupa menos espacio en nuestro disco duro: los archivos propios que tiene R con extensiones .rda o .RData. De nuestra carpeta DATOS cargaremos el archivo titanic.RData, un archivo con extensión .RData, conteniendo los datos de los pasajeros del Titanic (nombre, título, cabina, si sobrevivió o no, edad, etc)
¿Cómo cargar archivos .RData?
Muy sencillo: como son ficheros nativos de R, basta con usar la función de carga load(), y dentro de los paréntesis la ruta del archivo que queramos cargar.
load("./DATOS/titanic.RData")Fíjate que, al fijar nuestro directorio de trabajo, no necesitamos toda la ruta, solo ./ (que nos arranca la ruta en la carpeta de nuestro proyecto) más la ruta dentro de la carpeta del proyecto. Ahora en el panel de entorno de la parte superior derecha tendremos un data.frame que antes no teníamos. Ya hemos visto que una función muy útil es head(), con argumento el nombre de un data.frame, que nos permite visualizar las primeras filas.
head(titanic)## PassengerId Survived Pclass
## 1 1 0 3
## 2 2 1 1
## 3 3 1 3
## 4 4 1 1
## 5 5 0 3
## 6 6 0 3
## Name Sex Age SibSp Parch
## 1 Braund, Mr. Owen Harris male 22 1 0
## 2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0
## 3 Heikkinen, Miss. Laina female 26 0 0
## 4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0
## 5 Allen, Mr. William Henry male 35 0 0
## 6 Moran, Mr. James male NA 0 0
## Ticket Fare Cabin Embarked
## 1 A/5 21171 7.2500 S
## 2 PC 17599 71.2833 C85 C
## 3 STON/O2. 3101282 7.9250 S
## 4 113803 53.1000 C123 S
## 5 373450 8.0500 S
## 6 330877 8.4583 Q15.2 Archivo .rda: pisos en Boston
Fuente original de los datos: https://doi.org/10.1016/0095-0696(78)90006-2
Muchas veces no tendremos un .Rdata sino un archivo .rda. El procedimiento para leerlo será el mismo
load("./DATOS/boston.rda")El dataset Boston está basado en el estudio que realizaron Harrison and Rubinfeld, 1978 en el que se pretende determinar la disposición de los compradores para pagar más por una vivienda en un entorno con mayor calidad del aire. El conjunto de datos contiene datos del área metropolitana de Boston, con datos de 560 vecindarios, midiendo 14 variables en cada uno.
Las variables están totalmente descritas en Harrison and Rubinfeld, 1978 pero podemos resumirlas de la siguiente forma:
-
medv: variable objetivo, representa la mediana del precio inmobiliario (en miles de dolares). -
Variables arquitectónicas:
rm(número medio de habitaciones) yage(porcentaje de propiedades construidas antes de 1940). -
Variables de vecindario:
crim(tasa de criminalidad),zn(porcentaje del territorio destinado a áreas residenciales),indus(porcentaje del territorio destinado al tejido industrial),chas( ¿hay río limitando la extensión en el territorio?),tax(coste de los servicios públicos),ptratio(ratio alumno-profesor),black(índice de población negra - sí, es un archivo vergonzoso, pero no viene mal ver los sesgo raciales de muchos de los datos que consumimos - calcualda como \(1000 ( B - 0.63)^2\), donde \(B\) es el procentaje de población negra) ylstat(porcentaje de la población con bajos ingresos). -
Variables de accesibilidad:
dis(distancia a oficinas de empleo) yrad(categoría indicando la accesibilidad a la red de autopistas, a mayor índice, mayor accesibilidad). -
Variables de calidad del aire:
nox(concentración anual de óxido de nitrógeno, en partes por 10 millones).
15.3 Desde paquete: estadísticas del Eurostat
Fuente original de los datos: Our World in Data
Una opción muy común es cargar datos desde paquetes que ya los tienen incorporadas (o los consiguen a través de una API). Uno de los ejemplos más útiles seguramente sea uno de los protagonistas de los últimos años debido a la pandemia ha sido la web Our World in Data, y en concreto los datos que han recopilado de covid y vacunación de todos los países del mundo. Y sí, podemos acceder a ellos directamente desde R a través del paquete {owidR}.
# install.packages("owidR")
library(owidR)Con la función owid_search() podemos introducir una palabra clave, para obtener el listado de datasets y su palabra clave.
15.4 Exportación de datos
Aunque se puede exportar en cualquier formato que puedas importar, vamos a ver las dos formas más útiles y eficientes de exportar datos en R:
- fichero
.RData. - fichero
.csv(un Excel sin formato para ser leído en cualquier sistema)
La exportación en fichero .RData es la opción más recomendable si tú o tu equipo solo trabajáis con R, es la opción nativa de fichero, para que su importación sea tan sencilla como una función load(). Para exportar en R.Data basta con uses la función save(), indícandole lo que quieres guardar y la ruta donde quieres guardarlo.
Es importante entender que la principal ventaja de exportar un fichero .RData es que no se está portando una tabla, o un fichero tabulado con un formato de filas y columnas: estás exportando cualquier cosa, cualquier variable de R, con la naturaleza de esa variable intacta, sin necesidad de pasarlo otro formato.
nombres <- c("javier", "carla")
# Exportamos en .RData la variable nombres
save(nombres, file = "./EXPORTAR/nombres.RData")Para tenerlo organizado, la orden anterior está hecha habiendo creado en nuestra carpeta del proyecto una carpeta EXPORTAR para guardar lo que vayamos exportando. Ese fichero solo podrá ser abierto por R, pero cuando lo cargemos, tendremos la variable nombres tal cual la hemos guardado.
No siempre trabajamos en R y a veces necesitamos una exportación de un data.frame o una tabla que podamos abrir en nuestra ordenador, ya sea para explicársela a alguien o para enviársela a otra persona. Para ello exportaremos en .csv, un fichero sin formato, y que es capaz de ser abierto por todo tipo de hojas de cálculo: basta que usemos la función write_csv() del paquete readr
# install.packages("readr") # solo la primera vez
library(readr)
# Exportamos en .csv el data.frame boston
write_csv(boston, file = "./EXPORTAR/boston.csv")WARNING: líneas de código en los errores
Dado que los errores del código nos vendrán referenciados en la consola por el número de línea donde fueron detectados, puede sernos muy útil mostrar dichos números en la barra lateral izquierda, yendo a Tools << Global Options << Code << Display << Show line numbers
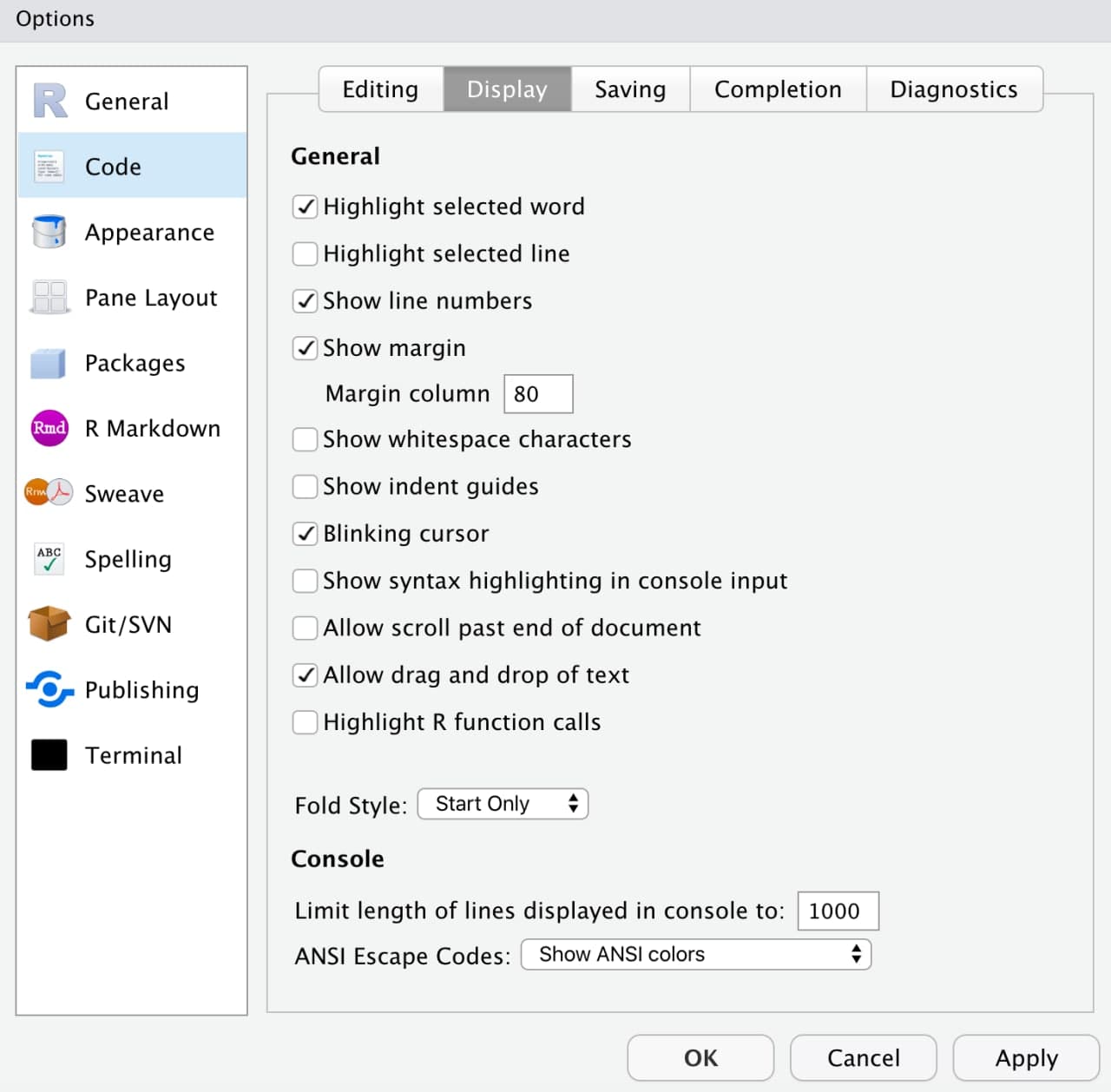
Imagen/gráfica 15.1: Líneas de código.
15.5 Consejos
CONSEJOS
Margen derecho en la ventana de scripts
Aunque no afecte a nuestro código escribir todo en una línea sin saltos de línea, no somos bárbaros/as. ¿Por qué cuadno escribes en un Word lo haces en formato vertical pero cuando programas pones todas las órdenes seguidas? Recuerda que la legibilidad de tu código no solo te ahorrará tiempo sino que te hará programar mejor. ¿Cómo podemos fijar un margen imaginario para nosotros ser quienes demos al ENTER? Yendo a Tools << Global Options << Code << Display << Show margin (es un margen imaginario para ser nosotros quienes lo hagamos efectivo, a R le da igual)
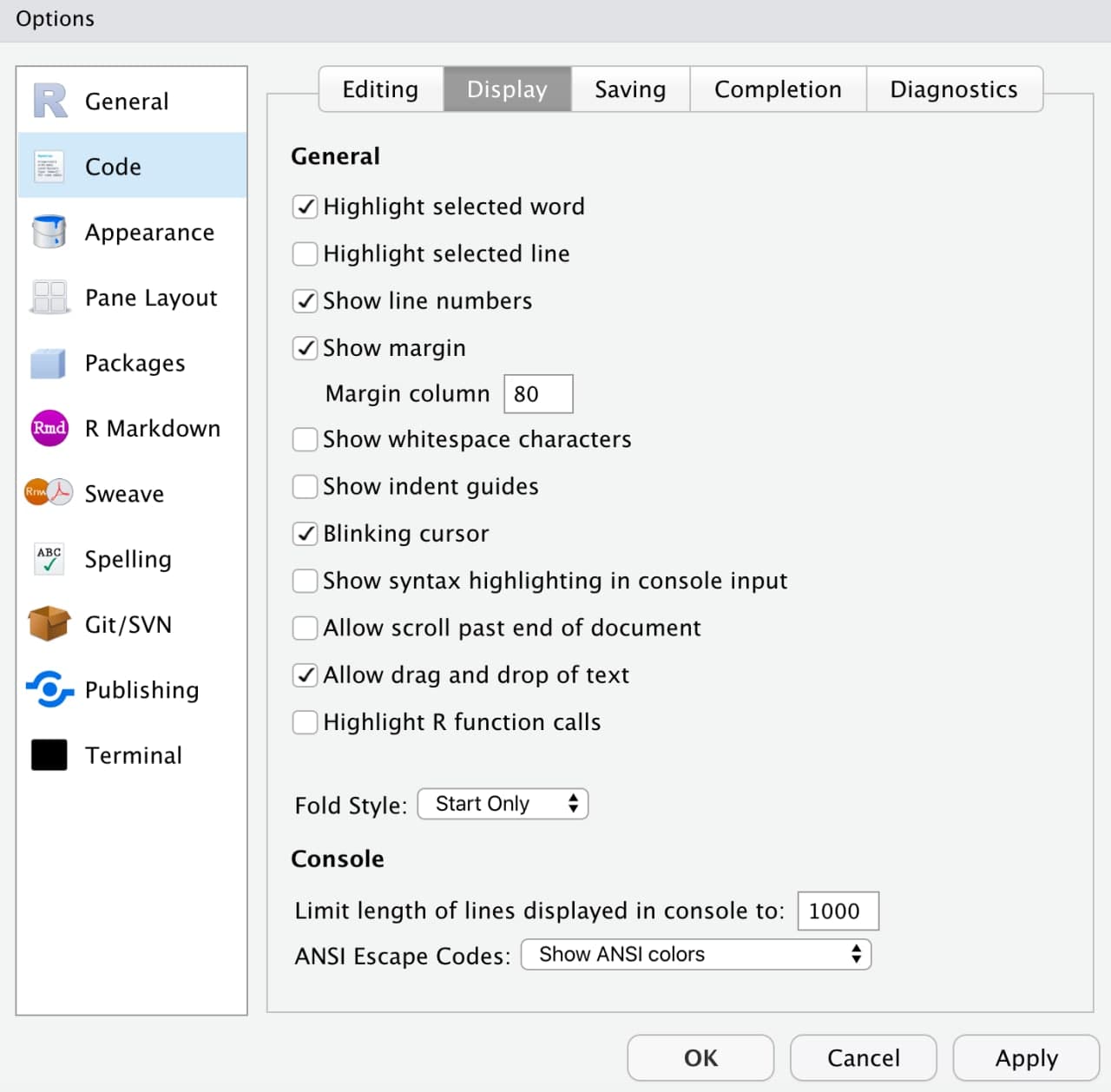
Imagen/gráfica 15.2: Margen derecho.